The dipped headlamp bulb blew on my Alfa Romeo GTV the other day and I spent way too long today working out how to replace it. What’s more, there didn’t seem to be clear instructions that I could find on the net, so I thought the decent thing to do would be to write it up here.
Why Are All the Good Ideas Already Taken?
The other evening on the way home from work, I had a brilliant idea. It was one of those that had been churning away in the back of my mind for a while but suddenly popped out, fully formed, in a way that hadn’t occurred to me before. This was it, this was going to be the interesting side project that had real traction.
I had been reading again about Netflix’s Chaos Monkey. It is a brilliant idea - in order to be good at something, you need to do it often, and therefore the best way of handling failure is to fail often. The other half of the equation was an approach to code-reviewing unit tests that I have been using for a while. If you can delete a line in the class under test, and the unit test still passes, then you didn’t need that line in the first place (although unfortunately it is usually the other way around - that more scenarios need to be added to the test). What if you could combine the two ideas? What if you had a system that would, as part of the build, randomly modify your source files and verify that your tests failed? That would be brilliant. It would be a really useful indicator of how good your tests actually are (and, for good measure, fully automate the net output of some of the less useful developers I have worked with over the years!).
The first thing I needed was something that understands Java syntax. More than that, I wanted to make use of a tool that is already capable of modifying Java source files. Understanding syntax was important because my first use case was going to be finding a magic number and incrementing it by one. Let’s look at an example method:
1 2 3 4 5 6 7 | |
and its associated test:
1 2 3 4 | |
So far, so trivial. It is a rather contrived example, but we have all seen more complicated examples of effectively the same issue in production code. The essential point is that we are all happy. The source compiles, it passes its tests, and the system behaves as expected. It is worth pointing out that a traditional test code coverage metric is no good here because the loop did execute when the test ran, so is considered to be covered. So, we run our test chaos monkey on our source code and let it increment a magic number by one.
1 2 3 4 5 6 7 | |
If we re-run our test now, we find that the test still passes. We have changed our source file in a meaningful way and yet our tests have not proven good enough to catch the changed behaviour. This, ladies and gentlemen, is what we in the trade call A Bad Thing™.
Also, this is where I get to the point. Five minutes of googling later I find out that, of course, this is already a known and understood way of testing. It is called Mutation Testing and people smarter than me have been doing it for years. Then, like all these sorts of questions, once you know the name for it all sorts of useful information comes flooding out of search engines. There is a stackoverflow question on how to integrate Java mutation testing with Maven and an answer directing me to PIT, an open source mutation testing tool. The question itself lists a bunch of other Java mutation testing tools; one of which, Jester, has been the subject of an IBM Developer Works article and a rather nice quote from Robert C. Martin on how it guided him to a more simple implementation of a test-driven coding exercise. So this really is not a new, cute, extension to our now traditional unit test safety net, but just me independently stumbling upon an idea that is apparently an already solved problem. That is great news from the point of view of getting this idea quickly in to practice in the day job, but just doesn’t feel as much fun as if it were my own idea.
So why are all the good ideas already taken? People smarter than you or I thought of them years ago.
HDD v SSD Compiling Benchmarks
If there ever was a subject that caused more unfounded claims and counter-claims, it’s performance benchmarking. Given the dearth of useful info I’ve been able to find about whether SSDs improve compilation time or not, I thought I would put up the numbers that I have found during a small test I did today.
Program to be compiled:
- Java webapp of ~10,000 executable lines of code
- Maven 3
- Java 1.6
New system:
- HP Compaq 8100 Elite Convertible Minitower PC
- Intel Core i7
- 6GB ram
- 64-bit Windows 7
- OCZ Vertex SATA SSD 60GB
- Barracuda 7200.12 SATA 3Gb/s 500GB HDD
Old system:
- Dell Dimension 9200
- Intel Core 2 6300
- 4GB ram
- SATA 260GB HDD
Benchmark Results
All times are as reported by Maven, not of the entire duration of the shell command.
Test command: mvn clean install

So, across the three build runs I performed on each environment, the timings are pleasingly consistent. The good news is that my new PC significantly outperforms my old one. The somewhat surprising news is that the HDD is consistently marginally quicker than the SSD. This suggests that this maven goal is not bound by disk I/O, that it is something else about my new system’s spec that gives such a performance boost. This actually reinforces what Joel Spolsky found when he ran a similar test a couple of years ago, and also one of the golden rules about working on performance - your assumptions will be wrong so measurement is king. Amen.
Reading Good to Great by Jim Collins
This book was recommended to me over a year ago but I only now have found the time to get myself a copy and read it.
Good to Great claims to be a fact-based investigation into what factors made a previously average-performing company change into one that significantly outperformed both the market and its competitors. I have only read the first fifty pages of the book so far, so can’t claim to either agree or disagree with just how well the evidence supports the book’s claims, but I think there are a couple of points that are worth highlighting based upon what I have read so far.
Firstly, of the eleven companies that meet that author’s criteria for having transformed from “good” to “great”, Fannie Mae and Gillette are the only two I have heard of. This isn’t good news as we all know how well Fannie Mae turned out. Given the book was written in 2001 and Fannie Mae’s spectacular collapse happened in 2008, it’s easy to snipe with the benefit of hindsight, but it can’t help tempering my view of just how “great” these selected companies really are. Jim Collins’s approach appears to have been to measure greatness by the value of a company’s stock returns, and I agree that a data-based metric of some kind is needed to make this comparative study worthwhile, but it is worth bearing in mind that there is much, much more to how great a company is than its performance on the stock market.
Secondly, one of the conclusions drawn is that they found no correlation between executive renumeration and company performance. That’s including performance and target-related incentives which is one of my own bug-bears. I have always found it mildly insulting to be offered a target-related bonus. They always seem to be used as a way modifying behaviour and, I think, entirely miss the point. Yes, money is the reason why we turn up for work but it’s my own job satisfaction that is the single most important goal once I’m there. Bonuses don’t typically make the difference between an income you’re happy with and one you’re not (would 10-15% of your salary really make that much difference, given that you can’t budget for it?). A bonus attached to a specific goal really doesn’t make me want to achieve that goal any more than I did already and, if that goal is in conflict with my perception of job satisfaction (doing the right thing for the job at hand), then there is something wrong here already. Either my understanding of what doing a good job looks like is wrong, or the incentivised target is wrong. Just setting the incentive doesn’t fix this - if I thought achieving it was part of doing a good job, then I would be doing everything I could to make it happen out of a need for job satisfaction alone. I have thought for a long time now that if you can pay people well to do a good job, then that’s exactly what you should do. You can then reasonably expect people to do a good job for you based upon mutual respect. It’s this mutual respect that I think is eroded by performance-based bonuses.
Given this is from the first fifty pages alone, there’s evidently quite a lot to digest in this one book. I’ll undoubtedly write more as I get through the book.
Good to great: why some companies make the leap… and others don’t Random House Business Books 2001 ISBN 9780712676090
Mocking iPhone Development
So now that I have ordinary-old unit testing is up and running, the next step is to get a mocking library in place so that I can simulate an external library’s behaviour under different scenarios.
OCMock seems to be the library of choice and the good news is that it appears to have a pretty neat API. The bad news comes when you want to, er, use it. I want to have the OCMock library only linked to my testing targets, which ought to be straight-forward enough, but following OCMock’s instructions rigorously only led me to pain. Here is a dead-simple test:
1 2 3 4 5 6 7 8 9 10 11 12 | |
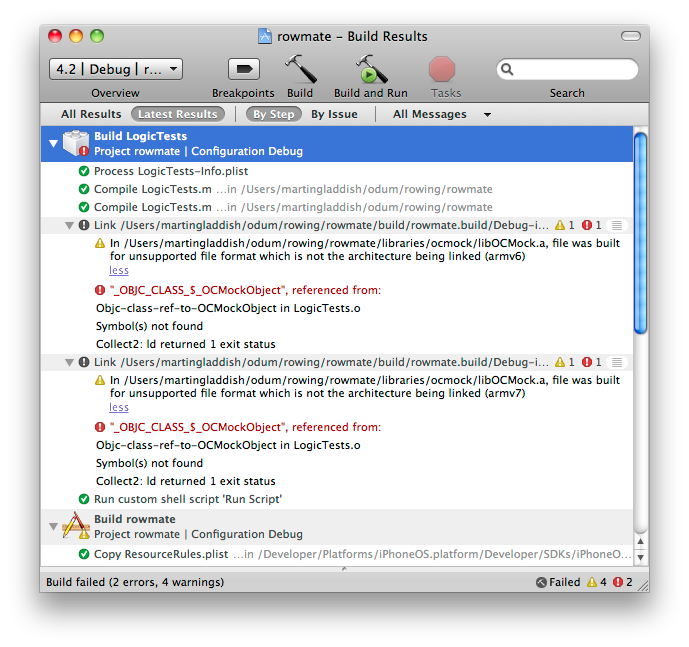
And the error that I get when trying to build the LogicTests target:

What’s going on here? XCode must recognise that the library is imported OK because it has OCMockObject correctly syntax highlighted, but the build fails at the linking stage. After much googling, Vincent Daubry appears to have the answer. It seems that there is some sort of incompatibility introduced between XCode 3.2.3, iOS4 and OCMock. Given that I am running XCode 3.2.5, iOS4 and OCMock 1.7, it felt likely that I had the same problem. Sure enough, replacing OCMock 1.7 with the latest version from its subversion repository did the trick. Annoyingly, 1.7 was released after Vincent’s post and I made the mistake of assuming that this more recent release would include the fix. Apparently not.
Having confirmed that having built OCMock from its source myself and using that rather than the released version 1.7 hadn’t broken any of the other project configurations led me to discover the next issue. Running the application on my device no longer works!
This appears to be because I made the application target depend upon the logic testing target, as suggested by Apple’s own documentation. This has the immense benefit that the tests are always run before running the application and ensures that the tests will be run regularly. I really can’t be bothered right now to work out how to resolve this1, so I will just have to make do with making my application target independent of my testing target, and make sure I remember to run my tests myself.
[1] My guess is that something along the lines of making the project’s Library Search Paths use the $(CONFIGURATION)$(EFFECTIVE_PLATFORM_NAME) variables to link to specific builds of OCMock ought to do the trick. I still don’t want my application to include references to its testing dependencies though, which this approach doesn’t solve.